
Introduction
Understanding the mechanisms by which large language models (LLMs) process information, store knowledge, and generate outputs remain key open questions in research [0, 1].
A persona is a natural language portrayal of an imagined individual belonging to some demographic group or reflecting certain personality traits [2]. Personas are often used to define the personality or perspective the LLM model should adopt when interacting with users, e.g., by prompting “Suppose you are a person who …” followed by a description of a particular trait or belief. This can significantly influence language generation by setting
 a tone appropriate for the context (e.g., empathetic or professional) and by affecting behavior and reasoning capabilities. Personas can enhance user experience and engagement by making models more relatable and context-aware, and can improve generated output. Personas have also attracted increasing attention, particularly in the development of trustworthy models [3, 4].
a tone appropriate for the context (e.g., empathetic or professional) and by affecting behavior and reasoning capabilities. Personas can enhance user experience and engagement by making models more relatable and context-aware, and can improve generated output. Personas have also attracted increasing attention, particularly in the development of trustworthy models [3, 4].
 Previous research has demonstrated that personas may elicit toxic responses and perpetuate stereotypes in language models [5], and can produce extreme political or cultural views [6]. Moreover, personas have been (mis)used to circumvent built-in safety mechanisms by instructing models to adopt specific roles [7]. Understanding how LLMs encode personas is essential for harm mitigation methods, aligning models with diverse beliefs, and tailoring outputs to users’ preferences.
Previous research has demonstrated that personas may elicit toxic responses and perpetuate stereotypes in language models [5], and can produce extreme political or cultural views [6]. Moreover, personas have been (mis)used to circumvent built-in safety mechanisms by instructing models to adopt specific roles [7]. Understanding how LLMs encode personas is essential for harm mitigation methods, aligning models with diverse beliefs, and tailoring outputs to users’ preferences.
In this work, we feed statements associated with different personas into various LLMs and extract their internal representations (i.e., activation vectors). We then analyze these representations to address the following two questions:
Where in the model are persona representations encoded? Specifically, which layers in the LLM exhibit the strongest signals for encoding persona-specific information?
How do these representations vary across different personas? In particular, are there consistent, uniquely activated locations within a given LLM layer where distinct persona representations are encoded?
Identifying Layers With Strongest Persona Representations
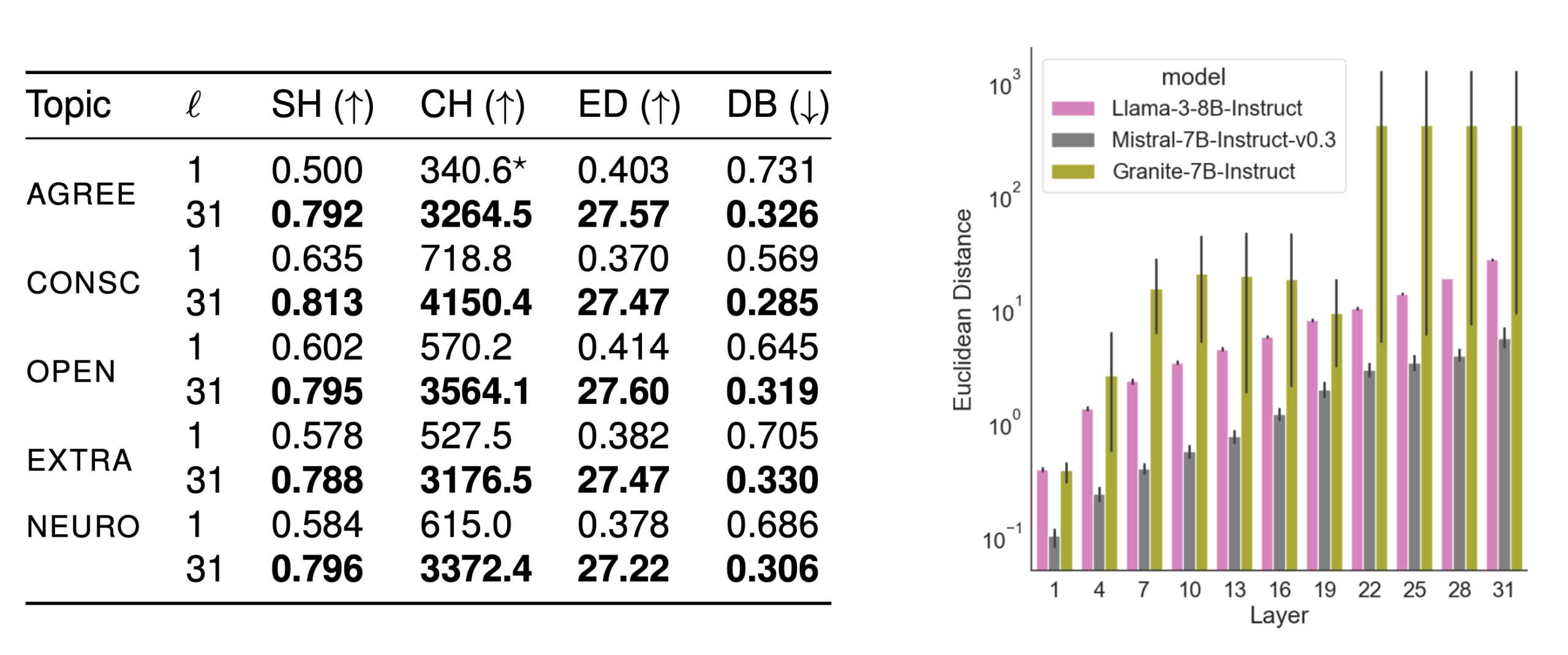
We first study which layers provide the strongest signals for encoding personas for different LLMs. Specifically, we identify the layer that exhibits the greatest divergence between the principal components (PCs) of the last token representations for sentences corresponding to a given persona. Our findings lay the groundwork for our next step, where we seek to localize sets of activations within a layer encoding persona information. Across the models, the largest distances are found in the later layers (20–31). The table reports additional metrics evaluating the separation, overlap, and compactness of the groups. Most measures indicate that the final layer of Llama3-8B-Instruct achieves the strongest separation. We find, however, that for some personas, certain metrics favor earlier layers or other models.
This suggests that while Llama3-8B-Instruct generally provides the best overall separation, for persona-specific applications, evaluating different metrics and models might be beneficial. Overall, later layers exhibit the greatest separation across LLMs, indicating that persona representations become increasingly refined, with final layers encoding the most discriminative features.
Identifying a Layer’s Activations With Strongest Persona Representations
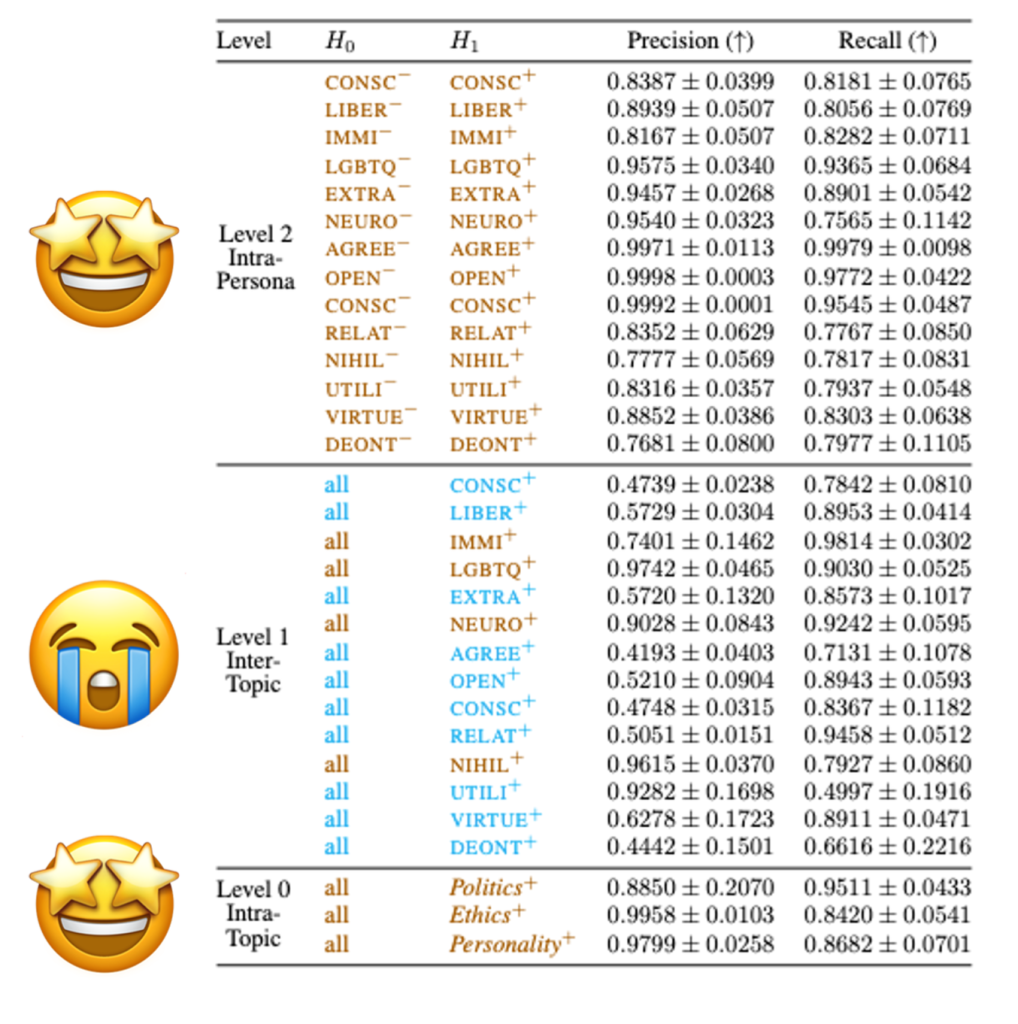
Next, we investigate whether distinct, consistent activation groups within a layer encode different personas. Building on our previous findings, we compare the last token representations from Llama3-8B-Instruct. We use Deep Scan [8,9, 10, 11] to identify the activation subsets most indicative of persona-specific information, which we refer to as salient activations.Before looking at subsets of salient activations, we need to validate the Deep Scan results across different levels of granularity. Which shows consistent performance for Level 2 and Level 0. That is why the following results are within these two granularities.
Politics personas display much lower overlap, with only 9.42% (386) shared activations across all.
For Ethics personas, only a small fraction of activations are unique—ranging from 0.37% (15 activations) to 1.39% (57).
 Significance
Significance
In this study, we analyze last token activations from 3 families of decoder-only LLMs using persona-specific statements from 14 datasets across Politics, Ethics, and Personality topics. We showed the strongest signal in separating persona information in final third of layers. Results suggested that political views have distinctly localized activations in the last layer of Llama3, and ethical values show greater polysemantic overlap.
Limitations & Future Work
While initial results, shed light into where representations are encoded. Our analyses are specific to the selected group of datasets and may not generalize well to other data sources. The datasets are written in English and primarily reflect WEIRD perspectives, and political views largely centered on U.S. politics. The dataset itself is LLM-generated, which has several shortcomings.
In the next coming months, we will explore a wider range of models, personas and datasets, and incorporate beliefs, values, and traits from more diverse cultural contexts. As well as investigate controlled editing of found internal representations.

Look out for our work @ AIES 2025 #119 Localizing Persona Representations in LLMs

Full paper with more details and experiments can be found in ArxIv and code in GitHub